load("your directory/YT_scraped_Data.RData")Data Linkage
Session 2c (2)
1 Link YouTube Datasets
Previously, we collected a few data sets from YouTube. These data sets are at different levels: comment, video, playlist, and channel. In analysis, it is common to model data from multiple levels and sources (such as the online data and survey data example we introduced last time). How can we make the data linkage in R?
Fig. 1 shows two types of data linkage. One is called append, which stacks two datasets together. As shown in the following figure, if two datasets, a and b, have identical rows but different columns, we can use cbind() to combine them together. If the data sets a and b have identical columns but different rows, we then use rbind().

Before running into the following examples, let’s load the YouTube data we’ve scrapped and created. You can download the scraped data here. And load the data in R. Also, load the tidyverse package.
library(tidyverse)Warning: package 'tidyverse' was built under R version 4.3.3Warning: package 'dplyr' was built under R version 4.3.3Warning: package 'stringr' was built under R version 4.3.3Warning: package 'lubridate' was built under R version 4.3.3── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.2 ✔ tibble 3.2.1
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.1.0
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors1.1 Append example
Let’s append the two channel-video datasets we have computed for the top 2 channels of TidyTuesday.
colnames(nren_all_channel_video_stats) [1] "id" "title" "publication_date" "description"
[5] "channel_id" "channel_title" "viewCount" "likeCount"
[9] "favoriteCount" "commentCount" "url" colnames(drob_all_channel_video_stats) [1] "id" "title" "publication_date" "description"
[5] "channel_id" "channel_title" "viewCount" "likeCount"
[9] "favoriteCount" "commentCount" "url" Since these two datasets have identical columns, we stack them together by rows and use rbind().
top2_all_channel_video_stats<-rbind(nren_all_channel_video_stats, drob_all_channel_video_stats)Let’s check if we did it right.
# row number is right
nrow(top2_all_channel_video_stats)==nrow(nren_all_channel_video_stats)+nrow(drob_all_channel_video_stats)[1] TRUE#columns are right as well
colnames(top2_all_channel_video_stats)==colnames(nren_all_channel_video_stats) [1] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE1.2 Merge data
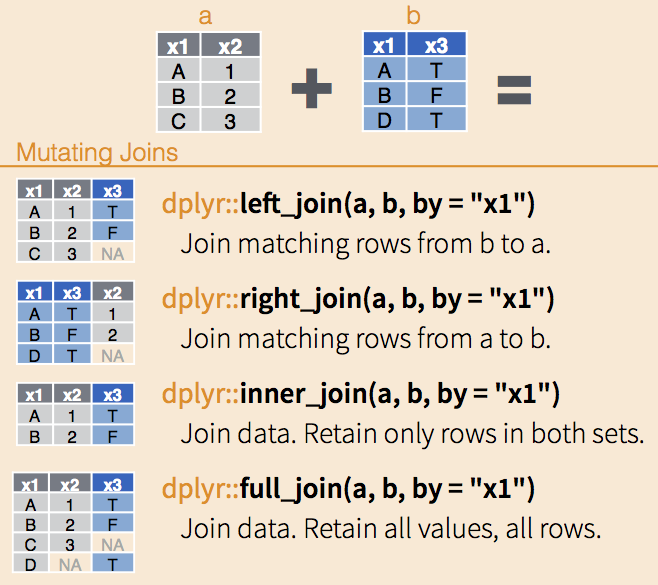
The other linkage type is called merge, which does not require two datasets with identical columns or rows. However, at least one common column is required. See the above figure. We call this common column “key.”
In tidyverse, merge is done by the *_join() family from the dplyr package. See the figure below for four main merge scenarios and the corresponding functions. The key column is specified in by="key". When the key column has different names from the two datasets, we specify it as by=c("name_from_a", "name_from_b")
Previously, we have comments data, comments.df, extracted from two videos. One video was actually from David’s TidyTuesday playlist. Now, I want to create a new comment dataset that only contains the comments on David’s video. In this new dataset, I also want to have the video’s information, such as the created time, counts of view and likes. The video information is in this data set: drob_all_channel_video_stats.
Let’s first rename the columns so that we can distinguish the column’s source. You can do this before the merge or after. I suggest to do this before merge.
comments.df<-comments.df %>%
rename_at(vars(-VideoID), ~ paste0(., "_ct")) # add a common suffix "_ct" indicting these variables come from the comments data and are at the comment level. However, not all the variables are at the comment level, such as VideoID.
drob_all_channel_video_stats<-drob_all_channel_video_stats %>%
rename_at(vars(-id), ~paste0(., "_ch")) # similarly, I add a common suffix "_ch" indicating the data source and level, which are channel. Again, we find the "id" variable is the video ID so I excluded it from renaming. We then join these two datasets, comments.df and drob_all_channel_video_stats. The key variable would be the ID variable of videos, which are “VideoID” and “id” variable in comments.df and drob_all_channel_video_stats correspondingly.
one_video_comment.df<-inner_join(comments.df, drob_all_channel_video_stats,
by=c("VideoID"="id"),
keep=F, # only the key from the dataset a, i.e., "VideoID", would be kept.
suffix = c(".ct", ".ch") # You can add suffix to distinguish any variables from the two datasets that have a same name. In this example, we don't have any duplicated variables (since we renamed they earlier) so we won't see any suffixes added.
) glimpse(one_video_comment.df)Rows: 4
Columns: 22
$ Comment_ct <chr> "this is great as usual, I pray that you find…
$ AuthorDisplayName_ct <chr> "@birasafabrice", "@s2737474", "@simonramirez…
$ AuthorProfileImageUrl_ct <chr> "https://yt3.ggpht.com/-p9B3cJqcuuEUgyt2w1WMV…
$ AuthorChannelUrl_ct <chr> "http://www.youtube.com/@birasafabrice", "htt…
$ AuthorChannelID_ct <chr> "UCkaDk6yajihpk7gOZVATkag", "UCVjbje1bA_A5mxz…
$ ReplyCount_ct <chr> "0", "0", "0", "0"
$ LikeCount_ct <chr> "3", "1", "1", "1"
$ PublishedAt_ct <chr> "2022-12-10T19:34:54Z", "2022-12-08T19:24:05Z…
$ UpdatedAt_ct <chr> "2022-12-10T19:34:54Z", "2022-12-08T19:24:05Z…
$ CommentID_ct <chr> "UgwuOobz_bK-Dt2NpaF4AaABAg", "UgxgUyke6SH_bq…
$ ParentID_ct <chr> NA, NA, NA, NA
$ VideoID <chr> "d7uFpxtiXyk", "d7uFpxtiXyk", "d7uFpxtiXyk", …
$ title_ch <chr> "Tidy Tuesday live screencast: Analyzing NYC …
$ publication_date_ch <chr> "2022-12-07T02:18:57Z", "2022-12-07T02:18:57Z…
$ description_ch <chr> "I'll analyze a dataset about NYC elevators, …
$ channel_id_ch <chr> "UCeiiqmVK07qhY-wvg3IZiZQ", "UCeiiqmVK07qhY-w…
$ channel_title_ch <chr> "David Robinson", "David Robinson", "David Ro…
$ viewCount_ch <chr> "4865", "4865", "4865", "4865"
$ likeCount_ch <chr> "107", "107", "107", "107"
$ favoriteCount_ch <chr> "0", "0", "0", "0"
$ commentCount_ch <chr> "4", "4", "4", "4"
$ url_ch <chr> "https://www.youtube.com/watch?v=d7uFpxtiXyk"…
Activity
Can you tell why we are using inner_join() instead of other joining functions?